
You are several to ask me to explain the implementation of the story points in a team. Let’s go with this article to try to answer your questions on the subject.
What are the story points in agile?
- the effort to do to develop the request
- the difficulty (complexity) that may be the demand
- the risks we imagine to meet during the development of the US
- any unknowns existing at the time of the estimate
- potential dependencies with external elements
We have to accept that the story points in agile are an “abstract” notion that can not be compared to a number of man days. But we can make predictability with it.
Yes, the story points in agile takes a notion of time contrary to what we can read sometimes. But its estimate is not based on it and this notion of time is not materialized by 1 story point = 1 day.
The Fibonacci sequence
Agile teams use this mathematical series because it represents this notion of estimation.
The Fibonacci sequence is: 1, 2, 3, 5, 8, 13 … In general, teams stop at 13 but I also see teams include 21.
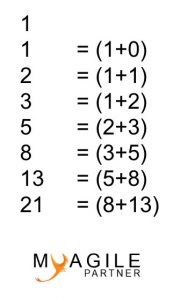
“The estimate comes more imprecise when it’s higher.”
This is why the Fibonacci sequence perfectly meets this idea.
In agile, it is considered that the difference between 12, 13 or 14 would be uninteresting. Indeed, high estimates in computer science can not be so precise because there are too many elements that can interfere. Thus, we will put 13 to represent an estimate that is into this estimation interval.
How can the team define their story points in agile?
It should be understood that each team will have its own referential at the level of the story points. Comparing the story points between two teams will not make sense.
1/ First estimation
During the first estimation session, we will ask the team to take into account the different concepts explained above. It’s not easy for teams the first time if they’ve never done it.
Don’t hesitate to put a small poster in the room so that each member of the team remembers the different points to take into account.

2/ First estimation reference
During the first estimates, we will ask the teams to define the “referent” requests so that the teams have a first estimation reference.
When the teams have estimated a request at “1”, we will put it as a reference of an estimate to 1. We will do the same thing with a request to 13.
This repository will be very useful for some teams who discover agile estimation. In this case, we will not hesitate to display this reference in the visual management of the team.
To estimate, the most well-known method today is poker planning. Here is an article that explains how it works:
Article: poker planning
3/ The estimate will evolve with time
Indeed, the estimate will evolve over time and will not be the same in the future. This is not a problem because in case of need of predictability, we will only take the last 3 sprints in reference.
Here are some reasons (the main ones) that will change the estimate of the team:
- the team will better know their environment
- the team will better know the context
- an arrival or departure will change the estimate
Managers or product owners should never force development teams to define a specific story point. They will have the necessary predictability even if the referential begins to evolve over time.
Simple example to understand the estimate
Here is an example that I like that helps to understand how the estimate effort point.
I present different types of vehicles:

Thus I explain to the team that they have to measure the story point to build these different vehicles. For this, they have to remember the essential concepts to take into account:
- difficulty
- effort of realization
- uncertainty
- risk
- dependencies.
Then, I present the first vehicle: “sports car of 300 horses” … I ask them to define the story points on it between 1 and 13. I don’t reveal the next vehicles.
So, the teams will together to say that it is possible to see a scooter or a rocket appear. This allows them to imagine how many story points is necessary to build the car if they compare with others potential vehicles.
Without even realizing it, the team will actually create its own referential.
I repeat the operation with each vehicle (which I have not disclosed before).
At the end of the exercise, I purpose to them to define the scooter as low reference (often imagined to 1) and the feri as high reference (often imagined to 13).
The team understands that it has created a referential of story points. Then you have to explain to them that it’s exactly the same thing in development.
Interesting special cases
The impossible estimate
In some cases, we will not necessarily be able to estimate the reqsuest. Here are some possible cases:
- need to look for solutions
- bug which we have no idea of the real problem
- data analysis (example in big data)
Then we will purpose to add a notion of spike that allows to define a time we give ourselves to answer a problem or hypothesis; these requests will not be estimated.
Article: Scrum spike: What’s a spike?
Avoid talking about complexity
Indeed, story points in agile is not only the estimation of the difficulty (complexity) of a request. Using this term often leads teams to misunderstand what a story point is.
Conclusion story points agile
I hope that this article have enlightened those who regularly ask me to explain more concretely how to define this estimate in story points within the agile teams.
Besides feel free to ask me for add-ons in comments if you do not have all the answers to your questions.
Useful link: video to understand story point (in french)

2 Trackbacks / Pingbacks